Building a Custom Chatbot using RAG

Table of Contents
Empower your Business and Customer Engagement with Generative AI
As businesses have undergone a digital transformation, companies are constantly looking for methods to boost productivity, drive innovation, and take advantage of cutting-edge technology to make workflow more efficient. With the help of Generative AI (GenAI), a trending branch of artificial intelligence, businesses in a variety of sectors can now automate laborious tasks and provide individualised enhanced experiences to their staff and customers.
And the application of GenAI to creating conversational agents, or Chatbots, has proven to streamline business flows and improve both internal and external engagement. It can significantly improve communication workflows, reduce operational costs by automating information retrieval processes and improves decision-making by delivering insightful information based on internal data.
RAG (Retrieval-Augmented Generation) is an effective technique that facilitates the creation of AI-based Chatbots based on a company’s internal data. This blog post provides a high-level overview of building a custom chatbot using RAG, covering the basic concepts, setting up the required environment and frameworks, designing the architecture, developing the chatbot and ultimately deploying it.
What is RAG (Retrieval-Augmented Generation)?
RAG is a novel approach that combines the advantages of information retrieval techniques and large language models (LLMs). The term was first coined and defined by Patrick Lewis, the lead author of the paper that introduced the concept [1]. The main idea of RAG is to enable a chatbot to generate factual responses based on internal data resources while querying other external resources to provide more accurate, relevant and human-like responses. Due to this, RAG is an ideal tool to create personalised chatbots that can respond to queries unique to a company or offer insights derived from internal data.
RAG is based on 2 major processes: Retrieval and Generation. During the retrieval process, relevant documents and information are fetched from the company’s internal database or predefined proprietary datasets based on user queries. The generation process then generates coherent, human-like responses in real-time based on the information that was retrieved.
Why use RAG instead of pretrained LLMs alone?
Without RAG, a chatbot built using LLMs such as Open AI’s GPT (Generative Pretrained Transformer) models alone, creates responses solely based on the information that it was trained on [2]. However, with RAG, the chatbot can utilise a company’s internal data sources that were not used during LLM training. The LLM then uses the factually accurate data that was retrieved and the vast amount of data it was already trained on to create natural and insightful responses to the query.
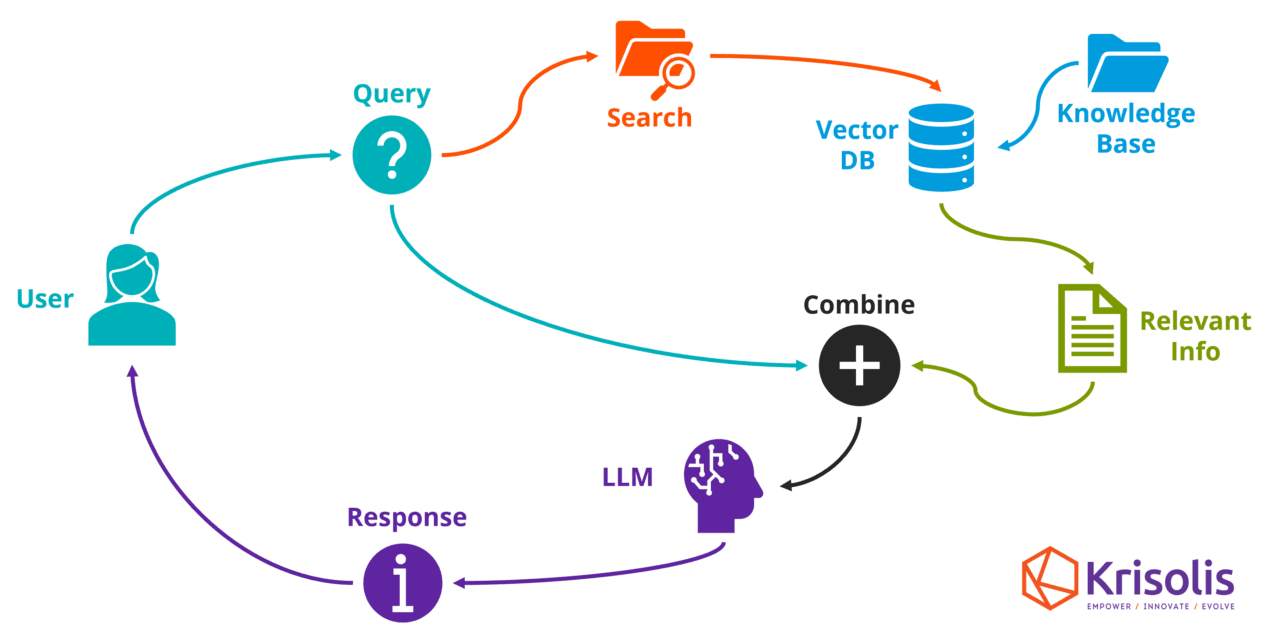
The main advantage of RAG is its adaptability. Retraining a pre trained LLM with completely new data resources is computationally and financially expensive. But with RAG, the process is made more efficient and cost-effective by simply swapping out the data it uses for knowledge retrieval while retaining and using the knowledge it was previously trained on [3].
High-level overview of Building a Chatbot using RAG
1. Identify the use case
First, it is essential to identify and clearly define the tasks and functionalities that the chatbot is required to perform. This may include retrieving information based on internal data and delivering customer support, personalised recommendations, comprehensive insights for decision-making, etc.
2. Prepare the knowledge base
Once the use cases are identified, it provides a way to select the data resources that contain the factually accurate and up-to-date information that may be required to respond to queries. Such data resources may include internal documents, user manuals, knowledge bases, FAQs, internal databases and other available datasets.
The documents gathered may need to undergo pre-processing to clean and remove noise or irrelevant information. The better the information the chatbot has access to, the better its responses will be.
After cleaning the documents are broken up into bite size chunks. Each chunk should encapsulate a complete thought or idea. This makes it easier for the system to identify and retrieve relevant material and for the LLM to process the retrieved information.
3. Create a vector database
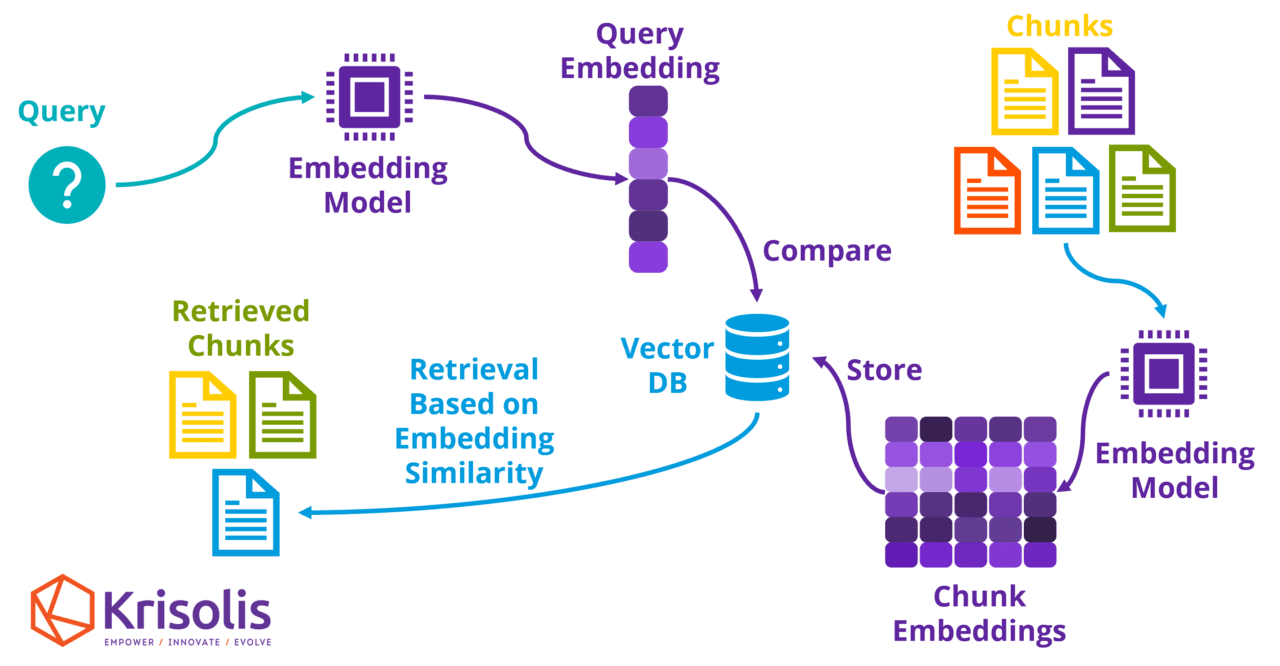
Each chunk is then converted into a numerical format using a machine learning model known as an embedding model. The embedding model transforms the text into vectors (a series of numbers) that capture the meaning and context of the text. Chunks of text with similar meanings will have similar vector representations.
Once the chunks have been embedded as vectors the vector representations are stored in a vector database. This allows for quick and efficient retrieval when you need to find specific information. These vector representations are known as embeddings.
4. Define the retrieval process
When a query is input, the system converts the query into an embedding using the same model that was used to create the vector representations of the chunks in the vector database. The query embedding is then compared with the stored chunk embeddings to find the most relevant chunks.
The most relevant chunks are those with embeddings that are most similar to the embedding of the user query. One way of measuring this similarity is simply to calculate the straight-line distance between the vectors, the closer the vectors are to each other in space the more similar the meaning of the underlying text.
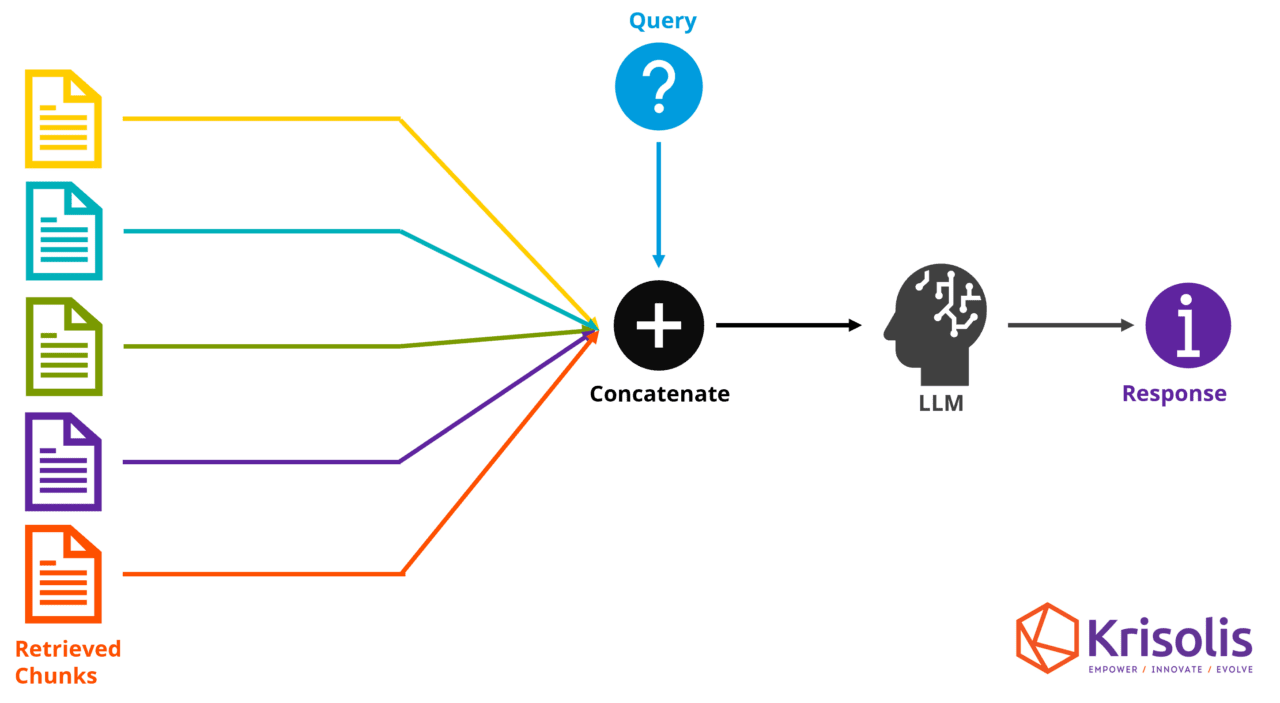
5. Integrate a pre-trained LLM (Generative Language Model)
A pre-trained LLM model can then be used to generate a coherent, natural response to the user’s query. It does this by summarizing and interpreting the retrieved content in the context of the user query.
6. Deploy the Chatbot
Once the chatbot is tested, monitored and ensured that it satisfies the initially defined use cases, it can be deployed as a chatbot with a user interface where customers can have natural conversation like having an interaction with a human agent who retrieves the requested information and responds in a contextually relevant manner.
If you are interested in getting hands-on experience on implementing a chatbot from scratch, our Build a Chatbot in a Day course offers an excellent one-day online session on the 20th of November 2024. You can register to reserve your spot to master building a RAG-based chatbot in a day.
References
[1] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
[2] https://aws.amazon.com/what-is/retrieval-augmented-generation/
[3] https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
[4] https://talwaitzenberg.com/mastering-rag-chabots-semantic-router-user-intents-ef3dea01afbc
[5] https://ledgerbox.io/blog/rag-techniques-function-calling

